Movie
Movie Controller
Controller

[English] 日本語
 Yorodumi
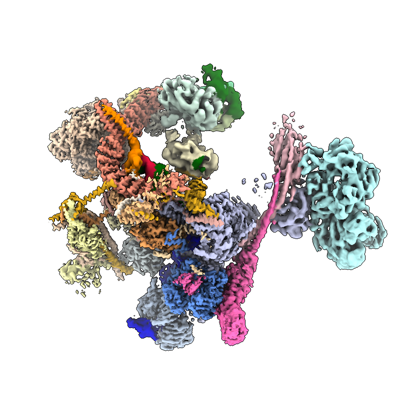
Yorodumi- EMDB-19397: Composite map of the C. elegans Intron Lariat Spliceosome primed ... -
+ Open data
Open data

- Basic information
Basic information
| Entry |  | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Title | Composite map of the C. elegans Intron Lariat Spliceosome primed for disassembly (ILS') | |||||||||
 Map data Map data | Composite Map | |||||||||
 Sample Sample |
| |||||||||
 Keywords Keywords | mRNA / splicing / Intorn Lariat spliceosome / ILS / pre-mRNA | |||||||||
| Function / homology |  Function and homology information Function and homology informationfeminization of hermaphroditic germ-line / molting cycle / regulation of primary miRNA processing / SLBP independent Processing of Histone Pre-mRNAs / snRNP Assembly / SLBP Dependent Processing of Replication-Dependent Histone Pre-mRNAs / Transport of Mature mRNA derived from an Intron-Containing Transcript / mRNA Splicing - Minor Pathway / Formation of TC-NER Pre-Incision Complex / Dual incision in TC-NER ...feminization of hermaphroditic germ-line / molting cycle / regulation of primary miRNA processing / SLBP independent Processing of Histone Pre-mRNAs / snRNP Assembly / SLBP Dependent Processing of Replication-Dependent Histone Pre-mRNAs / Transport of Mature mRNA derived from an Intron-Containing Transcript / mRNA Splicing - Minor Pathway / Formation of TC-NER Pre-Incision Complex / Dual incision in TC-NER / Gap-filling DNA repair synthesis and ligation in TC-NER / Downregulation of SMAD2/3:SMAD4 transcriptional activity / mRNA Splicing - Major Pathway / germline cell cycle switching, mitotic to meiotic cell cycle / mRNA 3'-end processing / RNA Polymerase II Transcription Termination / vulval development / nematode larval development / egg-laying behavior / post-spliceosomal complex / spliceosomal complex disassembly / U2-type post-mRNA release spliceosomal complex / spliceosomal conformational changes to generate catalytic conformation / post-mRNA release spliceosomal complex / generation of catalytic spliceosome for first transesterification step / apoptotic DNA fragmentation / nuclear mRNA surveillance / nuclease activity / U12-type spliceosomal complex / spliceosome conformational change to release U4 (or U4atac) and U1 (or U11) / embryo development ending in birth or egg hatching / pre-mRNA binding / U2-type catalytic step 1 spliceosome / pICln-Sm protein complex / RNA splicing, via transesterification reactions / SMN-Sm protein complex / spliceosomal tri-snRNP complex / P granule / snRNP binding / commitment complex / mRNA cis splicing, via spliceosome / U2-type catalytic step 2 spliceosome / U2-type spliceosomal complex / locomotion / U1 snRNP / U2 snRNP / U4 snRNP / U2-type prespliceosome / cyclosporin A binding / generation of catalytic spliceosome for second transesterification step / precatalytic spliceosome / uterus development / mRNA 3'-splice site recognition / germ cell development / spliceosomal tri-snRNP complex assembly / Prp19 complex / U5 snRNP / U5 snRNA binding / pre-mRNA intronic binding / U2 snRNA binding / U6 snRNA binding / protein K63-linked ubiquitination / spliceosomal snRNP assembly / U1 snRNA binding / U4/U6 x U5 tri-snRNP complex / catalytic step 2 spliceosome / RNA splicing / helicase activity / peptidylprolyl isomerase / peptidyl-prolyl cis-trans isomerase activity / RNA polymerase II transcription regulatory region sequence-specific DNA binding / spliceosomal complex / mRNA splicing, via spliceosome / RING-type E3 ubiquitin transferase / metallopeptidase activity / mRNA processing / ubiquitin-protein transferase activity / ubiquitin protein ligase activity / regulation of gene expression / protein folding / nucleic acid binding / DNA-binding transcription factor activity, RNA polymerase II-specific / cell differentiation / RNA helicase activity / RNA helicase / DNA repair / mRNA binding / GTPase activity / apoptotic process / regulation of transcription by RNA polymerase II / positive regulation of DNA-templated transcription / GTP binding / ATP hydrolysis activity / DNA binding / RNA binding / zinc ion binding / nucleoplasm / ATP binding / nucleus / cytosol Similarity search - Function | |||||||||
| Biological species |  | |||||||||
| Method | single particle reconstruction / cryo EM / Resolution: 2.9 Å | |||||||||
 Authors Authors | Vorlaender MK / Rothe P / Plaschka C | |||||||||
| Funding support | European Union, 1 items
| |||||||||
 Citation Citation | Journal: Nature / Year: 2024 Title: Mechanism for the initiation of spliceosome disassembly. Authors: Matthias K Vorländer / Patricia Rothe / Justus Kleifeld / Eric D Cormack / Lalitha Veleti / Daria Riabov-Bassat / Laura Fin / Alex W Phillips / Luisa Cochella / Clemens Plaschka /   Abstract: Precursor-mRNA (pre-mRNA) splicing requires the assembly, remodelling and disassembly of the multi-megadalton ribonucleoprotein complex called the spliceosome. Recent studies have shed light on ...Precursor-mRNA (pre-mRNA) splicing requires the assembly, remodelling and disassembly of the multi-megadalton ribonucleoprotein complex called the spliceosome. Recent studies have shed light on spliceosome assembly and remodelling for catalysis, but the mechanism of disassembly remains unclear. Here we report cryo-electron microscopy structures of nematode and human terminal intron lariat spliceosomes along with biochemical and genetic data. Our results uncover how four disassembly factors and the conserved RNA helicase DHX15 initiate spliceosome disassembly. The disassembly factors probe large inner and outer spliceosome surfaces to detect the release of ligated mRNA. Two of these factors, TFIP11 and C19L1, and three general spliceosome subunits, SYF1, SYF2 and SDE2, then dock and activate DHX15 on the catalytic U6 snRNA to initiate disassembly. U6 therefore controls both the start and end of pre-mRNA splicing. Taken together, our results explain the molecular basis of the initiation of canonical spliceosome disassembly and provide a framework to understand general spliceosomal RNA helicase control and the discard of aberrant spliceosomes. | |||||||||
| History |
|
- Structure visualization
Structure visualization
| Supplemental images |
|---|
- Downloads & links
Downloads & links
-EMDB archive
| Map data | emd_19397.map.gz | 8.6 MB | EMDB map data format | |
|---|---|---|---|---|
| Header (meta data) | emd-19397-v30.xmlemd-19397.xml | 60.8 KB 60.8 KB | Display Display | EMDB header |
| Images |  emd_19397.png emd_19397.png | 136.7 KB | ||
| Filedesc metadata | emd-19397.cif.gz | 18.7 KB | ||
| Archive directory |  http://ftp.pdbj.org/pub/emdb/structures/EMD-19397ftp://ftp.pdbj.org/pub/emdb/structures/EMD-19397 http://ftp.pdbj.org/pub/emdb/structures/EMD-19397ftp://ftp.pdbj.org/pub/emdb/structures/EMD-19397 | HTTPS FTP |
-Related structure data
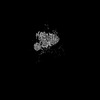
| Related structure data |  8ro0MC 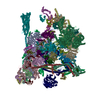 8ro1C  8ro2C  9fmdC C: citing same article ( M: atomic model generated by this map |
|---|---|
| Similar structure data |
































-Links
| EMDB pages | EMDB (EBI/PDBe) / EMDataResource |
|---|---|
| Related items in Molecule of the Month |



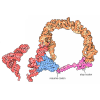
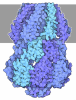
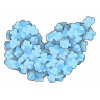
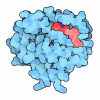
-Map
| File | Download / File: emd_19397.map.gz / Format: CCP4 / Size: 343 MB / Type: IMAGE STORED AS FLOATING POINT NUMBER (4 BYTES) | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Annotation | Composite Map | ||||||||||||||||||||||||||||||||||||
| Projections & slices | Image control
Images are generated by Spider. | ||||||||||||||||||||||||||||||||||||
| Voxel size | X=Y=Z: 1.3013 Å | ||||||||||||||||||||||||||||||||||||
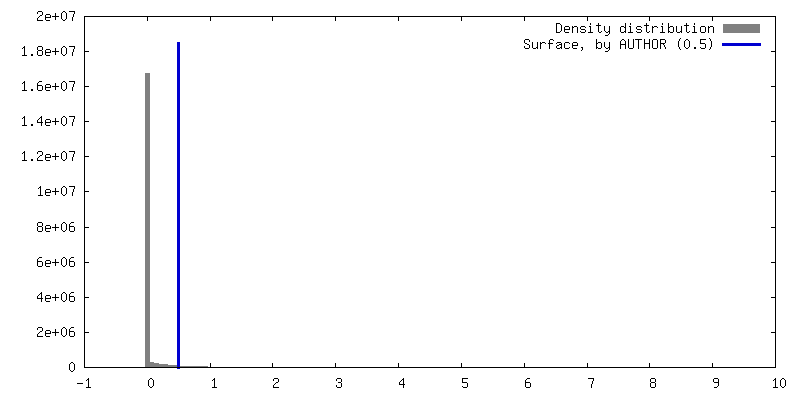
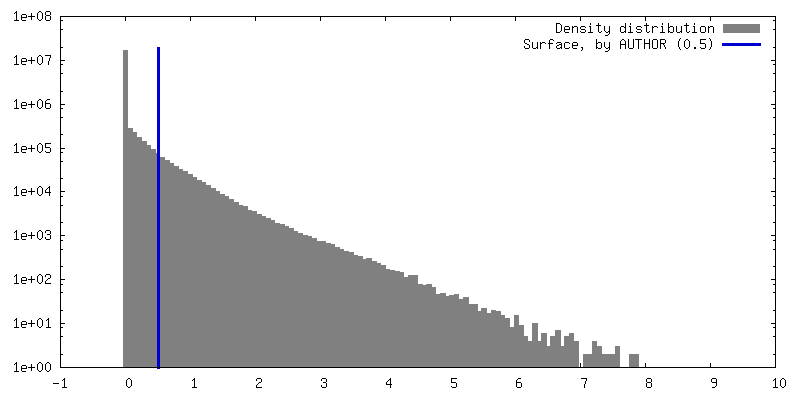
| Density |
| ||||||||||||||||||||||||||||||||||||
| Symmetry | Space group: 1 | ||||||||||||||||||||||||||||||||||||
| Details | EMDB XML:
|
 Z (Sec.)
Z (Sec.) Y (Row.)
Y (Row.) X (Col.)
X (Col.)


















-Supplemental data
- Sample components
Sample components
+Entire : Intron lariat spliceosome
+Supramolecule #1: Intron lariat spliceosome
+Macromolecule #1: U2 snRNA
+Macromolecule #2: U5 snRNA
+Macromolecule #3: U6 snRNA
+Macromolecule #4: Pre-mRNA-splicing factor 8 homolog
+Macromolecule #5: U5 small nuclear ribonucleoprotein 200 kDa helicase
+Macromolecule #6: Tr-type G domain-containing protein
+Macromolecule #7: Protein isy-1
+Macromolecule #8: WD_REPEATS_REGION domain-containing protein
+Macromolecule #9: Pre-mRNA-splicing factor SYF1
+Macromolecule #10: TPR_REGION domain-containing protein
+Macromolecule #11: Pre-mRNA-splicing factor SPF27
+Macromolecule #12: Cell division cycle 5-like protein
+Macromolecule #13: Pre-mRNA-splicing factor syf-2
+Macromolecule #14: Protein BUD31 homolog
+Macromolecule #15: Pre-mRNA-splicing factor RBM22
+Macromolecule #16: Spliceosome-associated protein CWC15 homolog
+Macromolecule #17: GCF C-terminal domain-containing protein
+Macromolecule #18: Intron-binding protein aquarius
+Macromolecule #19: Uncharacterized protein T27F2.1
+Macromolecule #20: Peptidyl-prolyl cis-trans isomerase
+Macromolecule #21: WD_REPEATS_REGION domain-containing protein
+Macromolecule #22: Septin and tuftelin-interacting protein 1 homolog
+Macromolecule #23: WD_REPEATS_REGION domain-containing protein
+Macromolecule #24: Coiled-coil domain-containing protein 12
+Macromolecule #25: Small nuclear ribonucleoprotein Sm D3
+Macromolecule #26: Probable small nuclear ribonucleoprotein-associated protein B
+Macromolecule #27: Small nuclear ribonucleoprotein Sm D1
+Macromolecule #28: Probable small nuclear ribonucleoprotein Sm D2
+Macromolecule #29: Probable small nuclear ribonucleoprotein E
+Macromolecule #30: Probable small nuclear ribonucleoprotein F
+Macromolecule #31: Probable small nuclear ribonucleoprotein G
+Macromolecule #32: Probable U2 small nuclear ribonucleoprotein A'
+Macromolecule #33: RRM domain-containing protein
+Macromolecule #34: Pre-mRNA-processing factor 19
+Macromolecule #35: Peptidyl-prolyl cis-trans isomerase E
+Macromolecule #36: Intron lariat RNA
+Macromolecule #37: MAGNESIUM ION
+Macromolecule #38: INOSITOL HEXAKISPHOSPHATE
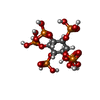
+Macromolecule #39: GUANOSINE-5'-TRIPHOSPHATE
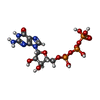
+Macromolecule #40: ZINC ION
-Experimental details
-Structure determination
| Method | cryo EM |
|---|---|
 Processing Processing | single particle reconstruction |
| Aggregation state | particle |
-Sample preparation
| Buffer | pH: 7.9 |
|---|---|
| Vitrification | Cryogen name: ETHANE |
| Details | Crosslinked with glutaraledhyde |
- Electron microscopy
Electron microscopy
| Microscope | FEI TITAN KRIOS |
|---|---|
| Image recording | Film or detector model: GATAN K3 BIOQUANTUM (6k x 4k) / Average electron dose: 60.0 e/Å2 |
| Electron beam | Acceleration voltage: 300 kV / Electron source:  FIELD EMISSION GUN FIELD EMISSION GUN |
| Electron optics | Illumination mode: FLOOD BEAM / Imaging mode: BRIGHT FIELD / Nominal defocus max: 2.0 µm / Nominal defocus min: 0.7000000000000001 µm |
| Experimental equipment |  Model: Titan Krios / Image courtesy: FEI Company |
-Image processing
| Startup model | Type of model: PDB ENTRY PDB model - PDB ID: |
|---|---|
| Final reconstruction | Resolution.type: BY AUTHOR / Resolution: 2.9 Å / Resolution method: FSC 0.143 CUT-OFF / Number images used: 879523 |
| Initial angle assignment | Type: MAXIMUM LIKELIHOOD |
| Final angle assignment | Type: MAXIMUM LIKELIHOOD |

-Atomic model buiding 1
| Initial model | Chain - Source name: AlphaFold / Chain - Initial model type: in silico model |
|---|---|
| Refinement | Protocol: AB INITIO MODEL |
| Output model | PDB-8ro0: |