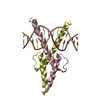
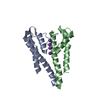
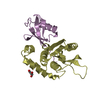
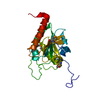
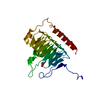
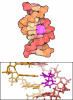
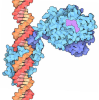
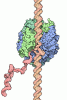
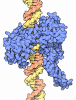
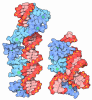
DNA (5'-D(*TP*CP*GP*AP*GP*CP*CP*GP*GP*AP*AP*GP*TP*TP*CP*GP*A)-3')
分子量: 5252.410 Da / 分子数: 1 / 由来タイプ: 合成
#2: DNA鎖
DNA (5'-D(*TP*CP*GP*AP*AP*CP*TP*TP*CP*CP*GP*GP*CP*TP*CP*GP*A)-3')
分子量: 5163.348 Da / 分子数: 1 / 由来タイプ: 合成
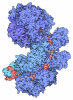
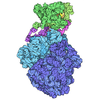
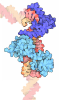
#3: タンパク質
ETS1
分子量: 11255.954 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: P14921
-
実験情報
-
実験
実験
手法: 溶液NMR
-
試料調製
試料状態
pH: 6.8 / 温度: 305.00 K
結晶化
*PLUS
手法: other / 詳細: NMR
-
NMR測定
NMRスペクトロメーター
タイプ
製造業者
モデル
磁場強度 (MHz)
Spectrometer-ID
Bruker AMX500
Bruker
AMX500
500
1
Bruker AMX600
Bruker
AMX600
600
2
-
解析
ソフトウェア
名称
バージョン
分類
X-PLOR
3.1
モデル構築
X-PLOR
3.1
精密化
X-PLOR
3.1
位相決定
NMR software
名称
分類
XPLOR
構造決定
XPLOR
精密化
精密化
手法: simulated annealing / ソフトェア番号: 1 詳細: THE RESTRAINED REGULARIZED MEAN STRUCTURE IS PRESENTED IN ENTRY 2STW AND 25 STRUCTURES ARE PRESENTED IN ENTRY 2STT. IN 2STW THE LAST COLUMN REPRESENTS THE RMS OF THE 25 INDIVIDUAL SIMULATED ...詳細: THE RESTRAINED REGULARIZED MEAN STRUCTURE IS PRESENTED IN ENTRY 2STW AND 25 STRUCTURES ARE PRESENTED IN ENTRY 2STT. IN 2STW THE LAST COLUMN REPRESENTS THE RMS OF THE 25 INDIVIDUAL SIMULATED ANNEALING STRUCTURES ABOUT THE MEAN COORDINATE POSITIONS. THE LAST COLUMN IN THE INDIVIDUAL SA STRUCTURES HAS NO MEANING. BEST FITTING TO GENERATE THE AVERAGE STRUCTURE IS WITH RESPECT TO RESIDUES 24 - 105 OF THE PROTEIN AND BASE PAIRS 1 - 17 OF THE DNA (RESIDUES 10 - 24 ARE DISORDERED IN SOLUTION). RESIDUE 10 CORRESPONDS TO RESIDUE 320 OF THE NATURAL SEQUENCE. NOTE THE OCCUPANCY FIELD HAS NO MEANING.
NMRアンサンブル
コンフォーマー選択の基準: REGULARIZED MEAN STRUCTURE 登録したコンフォーマーの数: 1
 ムービー
ムービー コントローラー
コントローラー

 データを開く
データを開く
 基本情報
基本情報 要素
要素 キーワード
キーワード 機能・相同性情報
機能・相同性情報 Homo sapiens (ヒト)
Homo sapiens (ヒト) データ登録者
データ登録者 引用
引用 構造の表示
構造の表示 ダウンロードとリンク
ダウンロードとリンク その他のダウンロード
その他のダウンロード


 PDBj
PDBj





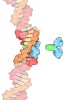




 集合体
集合体
 試料調製
試料調製 解析
解析 X-PLOR
X-PLOR