ムービー
ムービー コントローラー
コントローラー

+ データを開く
データを開く

- 基本情報
基本情報
| 登録情報 | データベース: PDB / ID: 7ptr | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
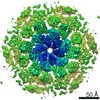
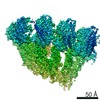
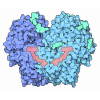
| タイトル | Structure of hexameric S-layer protein from Haloferax volcanii archaea | ||||||||||||
 要素 要素 | Cell surface glycoprotein | ||||||||||||
 キーワード キーワード | STRUCTURAL PROTEIN / S-layer csg | ||||||||||||
| 機能・相同性 | Surface glycoprotein signal peptide / Major cell surface glycoprotein / PGF-CTERM archaeal protein-sorting signal / PGF-CTERM motif / S-layer / cell wall organization / plasma membrane / beta-D-glucopyranose / Cell surface glycoprotein 機能・相同性情報 機能・相同性情報 | ||||||||||||
| 生物種 |  Haloferax volcanii DS2 (古細菌) Haloferax volcanii DS2 (古細菌) | ||||||||||||
| 手法 | 電子顕微鏡法 / 単粒子再構成法 / クライオ電子顕微鏡法 / 解像度: 3.46 Å | ||||||||||||
 データ登録者 データ登録者 | von Kuegelgen, A. / Bharat, T.A.M. | ||||||||||||
| 資金援助 |  英国, 3件 英国, 3件
| ||||||||||||
 引用 引用 | ジャーナル: Cell Rep / 年: 2021 タイトル: Complete atomic structure of a native archaeal cell surface. 著者: Andriko von Kügelgen / Vikram Alva / Tanmay A M Bharat /  要旨: Many prokaryotic cells are covered by an ordered, proteinaceous, sheet-like structure called a surface layer (S-layer). S-layer proteins (SLPs) are usually the highest copy number macromolecules in ...Many prokaryotic cells are covered by an ordered, proteinaceous, sheet-like structure called a surface layer (S-layer). S-layer proteins (SLPs) are usually the highest copy number macromolecules in prokaryotes, playing critical roles in cellular physiology such as blocking predators, scaffolding membranes, and facilitating environmental interactions. Using electron cryomicroscopy of two-dimensional sheets, we report the atomic structure of the S-layer from the archaeal model organism Haloferax volcanii. This S-layer consists of a hexagonal array of tightly interacting immunoglobulin-like domains, which are also found in SLPs across several classes of archaea. Cellular tomography reveal that the S-layer is nearly continuous on the cell surface, completed by pentameric defects in the hexagonal lattice. We further report the atomic structure of the SLP pentamer, which shows markedly different relative arrangements of SLP domains needed to complete the S-layer. Our structural data provide a framework for understanding cell surfaces of archaea at the atomic level. | ||||||||||||
| 履歴 |
|
- 構造の表示
構造の表示
| ムービー |
ムービービューア |
|---|---|
| 構造ビューア | 分子: MolmilJmol/JSmol |
- ダウンロードとリンク
ダウンロードとリンク
-ダウンロード
| PDBx/mmCIF形式 | 7ptr.cif.gz | 689 KB | 表示 | PDBx/mmCIF形式 |
|---|---|---|---|---|
| PDB形式 | pdb7ptr.ent.gz | 572.6 KB | 表示 | PDB形式 |
| PDBx/mmJSON形式 | 7ptr.json.gz | ツリー表示 | PDBx/mmJSON形式 | |
| その他 |  その他のダウンロード その他のダウンロード |
-検証レポート
| アーカイブディレクトリ | https://data.pdbj.org/pub/pdb/validation_reports/pt/7ptrftp://data.pdbj.org/pub/pdb/validation_reports/pt/7ptr | HTTPS FTP |
|---|
-関連構造データ











-リンク
 PDBj
PDBj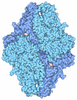

- 集合体
集合体
| 登録構造単位 | 
|
|---|---|
| 1 |
|
-要素
| #1: タンパク質 | 分子量: 81755.602 Da / 分子数: 6 / 由来タイプ: 天然 / 由来: (天然) Haloferax volcanii DS2 (古細菌) / Plasmid details: Allers et al 2004 / 参照: UniProt: P25062#2: 化合物 | ChemComp-CA /   分子量: 40.078 Da / 分子数: 18 / 由来タイプ: 合成 / 式: Ca / タイプ: SUBJECT OF INVESTIGATION 分子量: 40.078 Da / 分子数: 18 / 由来タイプ: 合成 / 式: Ca / タイプ: SUBJECT OF INVESTIGATION#3: 糖 | ChemComp-BGC / 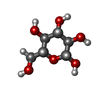  タイプ: D-saccharide, beta linking / 分子量: 180.156 Da / 分子数: 18 / 由来タイプ: 合成 / 式: C6H12O6 / タイプ: SUBJECT OF INVESTIGATION タイプ: D-saccharide, beta linking / 分子量: 180.156 Da / 分子数: 18 / 由来タイプ: 合成 / 式: C6H12O6 / タイプ: SUBJECT OF INVESTIGATION研究の焦点であるリガンドがあるか | Y | Has protein modification | Y | |
|---|
-実験情報
-実験
| 実験 | 手法: 電子顕微鏡法 |
|---|---|
| EM実験 | 試料の集合状態: 2D ARRAY / 3次元再構成法: 単粒子再構成法 |
- 試料調製
試料調製
| 構成要素 | 名称: Structure of hexameric S-layer protein csg / タイプ: COMPLEX / 詳細: Structure of hexameric S-layer protein csg / Entity ID: #1 / 由来: NATURAL | |||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 分子量 | 実験値: NO | |||||||||||||||||||||||||
| 由来(天然) | 生物種: Haloferax volcanii DS2 (古細菌) / 細胞内の位置: Cell surface | |||||||||||||||||||||||||
| 緩衝液 | pH: 7.5 詳細: Buffer solutions were prepared fresh from sterile filtered concentrated stocksolutions. Solutions were filtered through a 0.22 um filter to avoid microbial contamination and degassed using a ...詳細: Buffer solutions were prepared fresh from sterile filtered concentrated stocksolutions. Solutions were filtered through a 0.22 um filter to avoid microbial contamination and degassed using a vacuum fold pump. The pH of the HEPES stock solution was adjusted with sodium hydroxide at 4 deg C. 15 mM Calcium chloride was added 15 minutes before vitrification. | |||||||||||||||||||||||||
| 緩衝液成分 |
| |||||||||||||||||||||||||
| 試料 | 濃度: 3.2 mg/ml / 包埋: NO / シャドウイング: NO / 染色: NO / 凍結: YES 詳細: Purified csg protein mixed with 15 mM CaCl2 after 15 minutes incubation. | |||||||||||||||||||||||||
| 試料支持 | 詳細: 20 seconds, 15 mA / グリッドの材料: COPPER/RHODIUM / グリッドのサイズ: 200 divisions/in. / グリッドのタイプ: Quantifoil R2/2 | |||||||||||||||||||||||||
| 急速凍結 | 装置: FEI VITROBOT MARK IV / 凍結剤: ETHANE / 湿度: 100 % / 凍結前の試料温度: 283.15 K 詳細: Vitrobot options: Blot time 4.5 seconds, Blot force -10,1, Wait time 10 seconds, Drain time 0.5 seconds |
- 電子顕微鏡撮影
電子顕微鏡撮影
| 実験機器 |  モデル: Titan Krios / 画像提供: FEI Company |
|---|---|
| 顕微鏡 | モデル: FEI TITAN KRIOS 詳細: EPU software with faster acquisition mode AFIS (Aberration Free Image Shift). |
| 電子銃 | 電子線源:  FIELD EMISSION GUN / 加速電圧: 300 kV / 照射モード: FLOOD BEAM FIELD EMISSION GUN / 加速電圧: 300 kV / 照射モード: FLOOD BEAM |
| 電子レンズ | モード: BRIGHT FIELD / 倍率(公称値): 81000 X / 倍率(補正後): 81000 X / 最大 デフォーカス(公称値): 4000 nm / 最小 デフォーカス(公称値): 1000 nm / Calibrated defocus min: 1000 nm / 最大 デフォーカス(補正後): 4000 nm / Cs: 2.7 mm / C2レンズ絞り径: 50 µm / アライメント法: ZEMLIN TABLEAU |
| 試料ホルダ | 凍結剤: NITROGEN 試料ホルダーモデル: FEI TITAN KRIOS AUTOGRID HOLDER 最高温度: 70 K / 最低温度: 70 K |
| 撮影 | 平均露光時間: 3.4 sec. / 電子線照射量: 51.441 e/Å2 フィルム・検出器のモデル: GATAN K3 BIOQUANTUM (6k x 4k) 撮影したグリッド数: 2 / 実像数: 18468 詳細: Images were collected in two sessions movie-mode and subjected to 3.4 seconds of exposure where a total dose of 49 or 51.441 e-/A2 was applied, and 40 frames were recorded per movie. A total ...詳細: Images were collected in two sessions movie-mode and subjected to 3.4 seconds of exposure where a total dose of 49 or 51.441 e-/A2 was applied, and 40 frames were recorded per movie. A total of 18468 movies were collected in two sessions with the same microscope and settings. |
| 電子光学装置 | エネルギーフィルター名称: GIF Quantum LS / エネルギーフィルタースリット幅: 20 eV |
| 画像スキャン | 横: 5760 / 縦: 4092 |
- 解析
解析
| ソフトウェア | 名称: PHENIX / バージョン: 1.19_4092: / 分類: 精密化 | ||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EMソフトウェア |
| ||||||||||||||||||||||||||||||||||||||||||||||||||
| 画像処理 | 詳細: Movies were clustered into optics groups based on the XML meta-data of the data-collection software EPU (ThermoFisher) using a k-means algorithm implemented in EPU_group_AFIS (https://github. ...詳細: Movies were clustered into optics groups based on the XML meta-data of the data-collection software EPU (ThermoFisher) using a k-means algorithm implemented in EPU_group_AFIS (https://github.com/DustinMorado/EPU_group_AFIS). Imported movies were motion-corrected, dose weighted, and Fourier cropped (2x) with MotionCor2 (Zheng et al., 2017) implemented in RELION3.1 (Zivanov et al., 2018). Contrast transfer functions (CTFs) of the resulting motion-corrected micrographs were estimated using CTFFIND4 (Rohou and Grigorieff, 2015). | ||||||||||||||||||||||||||||||||||||||||||||||||||
| CTF補正 | 詳細: RELION refinement with in-built CTF correction. The function is similar to a Wiener filter, so amplitude correction included. タイプ: PHASE FLIPPING AND AMPLITUDE CORRECTION | ||||||||||||||||||||||||||||||||||||||||||||||||||
| 粒子像の選択 | 選択した粒子像数: 10558369 詳細: Top and tilted views were manually picked at the central hexameric axis. Manually picked particles were extracted in 4x downsampled 100 x 100 boxes and classified using reference-free 2D ...詳細: Top and tilted views were manually picked at the central hexameric axis. Manually picked particles were extracted in 4x downsampled 100 x 100 boxes and classified using reference-free 2D classification inside RELION3.1 (Zivanov et al., 2020). Class averages centered at a hexameric axis were used to automatically pick particles inside RELION3.1. Automatically picked particles were extracted in 4x downsampled 100x100 pixel boxes and classified using reference-free 2D classification. Particle coordinates belonging to class averages centered at the hexameric axis were used to train TOPAZ (Bepler et al., 2019) in 5x downsampled micrographs with the neural network architecture ResNet8. For the final reconstruction, particles were picked using TOPAZ and the previously trained neural network above. Additionally, top and bottom views were picked using the reference-based autopicker inside RELION3.1, which were not readily identified by TOPAZ. Particles were extracted in 4x downsampled 100 x 100 boxes and classified using reference-free 2D classification inside RELION3.1. Particles belonging to class averages centered at the hexameric axis were combined, and particles within 100 angstrom were removed to prevent duplication after alignment. | ||||||||||||||||||||||||||||||||||||||||||||||||||
| 対称性 | 点対称性: C6 (6回回転対称) | ||||||||||||||||||||||||||||||||||||||||||||||||||
| 3次元再構成 | 解像度: 3.46 Å / 解像度の算出法: FSC 0.143 CUT-OFF / 粒子像の数: 1087798 / アルゴリズム: FOURIER SPACE 詳細: Particles from classes with the same curvature were combined, re-extracted in 400 x 400 boxes and subjected to a focused 3D auto refinement on the central 6 subunits using the scaled and ...詳細: Particles from classes with the same curvature were combined, re-extracted in 400 x 400 boxes and subjected to a focused 3D auto refinement on the central 6 subunits using the scaled and lowpass filtered output from the 3D classification as a starting model. Per-particle defocus, anisotropy magnification and higher-order aberrations were refined inside RELION3.1, followed by another round of focused 3D auto refinement and Bayesian particle polishing (Zivanov et al., 2020). クラス平均像の数: 1 / 対称性のタイプ: POINT | ||||||||||||||||||||||||||||||||||||||||||||||||||
| 原子モデル構築 | B value: 143.26 / プロトコル: AB INITIO MODEL / 空間: REAL / Target criteria: Best Fit 詳細: The boundaries of the six Ig-like domains, D1-D6, were predicted using HHpred (Steinegger et al., 2019) in default settings within the MPI Bioinformatics Toolkit (Zimmermann et al., 2018). ...詳細: The boundaries of the six Ig-like domains, D1-D6, were predicted using HHpred (Steinegger et al., 2019) in default settings within the MPI Bioinformatics Toolkit (Zimmermann et al., 2018). Subsequently, structural models for these domains were built using the Robetta structure prediction server, employing the deep learning-based modelling method TrRosetta (Yang et al., 2020). The obtained structural models of domains D3-D6 resulted in an overall fit into the hexameric cryo-EM map of csg from the reconstituted sheets. D1-D2 deviated significantly from any obtained homology models, and for those domains, the carbon backbone of the csg protein was manually traced through a single subunit of the hexameric cryo-EM density using Coot (Emsley and Cowtan, 2004). Due to the edge effect of the box used in the refinement of the 3.5 angstrom map, parts of D6 displayed edge artefacts. These artefacts were removed using single-particle cryo-EM refinement in a larger box, which led to an overall slightly lower resolution (3.8 angstrom) but allowed fitting of the D6 homology model unambiguously. Following initial manual building (for D1-D2) or fitting in of structural models (for D3-D6), side chains were assigned in regions with density corresponding to characteristic aromatic residues allowing us to deduce the register of the amino acid sequence in the map. Another important check of the model building was the position of known glycan positions, which were readily assigned based on large unexplained densities on characteristic asparagine residues. The atomic model was then placed into the hexameric map in six copies and subjected to several rounds of refinement using refmac5 (Murshudov et al., 2011) inside the CCP-EM software suite (Burnley et al., 2017) and PHENIX (Liebschner et al., 2019), followed by manually rebuilding in Coot (Emsley and Cowtan, 2004). Model validation was performed in PHENIX and CCP-EM. |