 ムービー
ムービー コントローラー
コントローラー

+ データを開く
データを開く

- 基本情報
基本情報
| 登録情報 | データベース: PDB / ID: 7kts | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
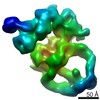
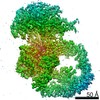
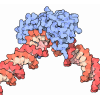
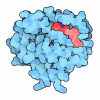
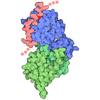
| タイトル | Negative stain EM structure of the human SAGA coactivator complex (TRRAP, core, splicing module) | |||||||||||||||||||||
 要素 要素 |
| |||||||||||||||||||||
 キーワード キーワード | TRANSCRIPTION / splicing / gene regulation / chromatin | |||||||||||||||||||||
| 機能・相同性 |  機能・相同性情報 機能・相同性情報SAGA-type complex / positive regulation of response to stimulus / regulation of somatic stem cell population maintenance / regulation of cellular response to stress / SAGA complex assembly / lateral mesodermal cell differentiation / allantois development / transcription factor TFTC complex / SLIK (SAGA-like) complex / splicing factor binding ...SAGA-type complex / positive regulation of response to stimulus / regulation of somatic stem cell population maintenance / regulation of cellular response to stress / SAGA complex assembly / lateral mesodermal cell differentiation / allantois development / transcription factor TFTC complex / SLIK (SAGA-like) complex / splicing factor binding / U12-type spliceosomal complex / negative regulation of microtubule depolymerization / hepatocyte differentiation / maintenance of protein location in nucleus / RNA splicing, via transesterification reactions / U2-type spliceosomal complex / U2-type precatalytic spliceosome / U2-type prespliceosome assembly / RNA polymerase binding / SAGA complex / U2 snRNP / limb development / transcription preinitiation complex / negative regulation of intrinsic apoptotic signaling pathway in response to DNA damage by p53 class mediator / NuA4 histone acetyltransferase complex / precatalytic spliceosome / nucleus organization / HIV Transcription Initiation / RNA Polymerase II HIV Promoter Escape / Transcription of the HIV genome / RNA Polymerase II Promoter Escape / RNA Polymerase II Transcription Pre-Initiation And Promoter Opening / RNA Polymerase II Transcription Initiation / RNA Polymerase II Transcription Initiation And Promoter Clearance / mRNA Splicing - Minor Pathway / regulation of RNA splicing / histone deacetylase complex / transcription factor TFIID complex / RNA polymerase II general transcription initiation factor activity / histone acetyltransferase complex / embryonic placenta development / positive regulation of transcription initiation by RNA polymerase II / U2 snRNA binding / regulation of DNA repair / somitogenesis / RNA polymerase II preinitiation complex assembly / gastrulation / RNA Polymerase II Pre-transcription Events / visual perception / TBP-class protein binding / catalytic step 2 spliceosome / mRNA Splicing - Major Pathway / RNA splicing / male germ cell nucleus / DNA-templated transcription initiation / promoter-specific chromatin binding / nuclear estrogen receptor binding / transcription initiation at RNA polymerase II promoter / transcription coregulator activity / spliceosomal complex / mRNA transcription by RNA polymerase II / multicellular organism growth / negative regulation of protein catabolic process / autophagy / nuclear matrix / cytoplasmic ribonucleoprotein granule / mRNA splicing, via spliceosome / microtubule cytoskeleton organization / G1/S transition of mitotic cell cycle / transcription corepressor activity / microtubule cytoskeleton / HATs acetylate histones / positive regulation of cell growth / DNA-binding transcription factor binding / Regulation of TP53 Activity through Phosphorylation / transcription by RNA polymerase II / transcription coactivator activity / protein stabilization / Ub-specific processing proteases / nuclear speck / chromatin remodeling / protein heterodimerization activity / DNA repair / focal adhesion / apoptotic process / protein-containing complex binding / regulation of DNA-templated transcription / nucleolus / regulation of transcription by RNA polymerase II / negative regulation of apoptotic process / positive regulation of DNA-templated transcription / perinuclear region of cytoplasm / Golgi apparatus / enzyme binding / negative regulation of transcription by RNA polymerase II / positive regulation of transcription by RNA polymerase II / DNA binding / RNA binding / extracellular exosome / nucleoplasm 類似検索 - 分子機能 | |||||||||||||||||||||
| 生物種 |  Homo sapiens (ヒト) Homo sapiens (ヒト) unclassified Rhodococcus (バクテリア) unclassified Rhodococcus (バクテリア) | |||||||||||||||||||||
| 手法 | 電子顕微鏡法 / 単粒子再構成法 / ネガティブ染色法 / 解像度: 19.09 Å | |||||||||||||||||||||
 データ登録者 データ登録者 | Herbst, D.A. / Esbin, M.N. / Nogales, E. | |||||||||||||||||||||
| 資金援助 |  米国, European Union, 米国, European Union,  スイス, 6件 スイス, 6件
| |||||||||||||||||||||
 引用 引用 | ジャーナル: Nat Struct Mol Biol / 年: 2021 タイトル: Structure of the human SAGA coactivator complex. 著者: Dominik A Herbst / Meagan N Esbin / Robert K Louder / Claire Dugast-Darzacq / Gina M Dailey / Qianglin Fang / Xavier Darzacq / Robert Tjian / Eva Nogales /  要旨: The SAGA complex is a regulatory hub involved in gene regulation, chromatin modification, DNA damage repair and signaling. While structures of yeast SAGA (ySAGA) have been reported, there are ...The SAGA complex is a regulatory hub involved in gene regulation, chromatin modification, DNA damage repair and signaling. While structures of yeast SAGA (ySAGA) have been reported, there are noteworthy functional and compositional differences for this complex in metazoans. Here we present the cryogenic-electron microscopy (cryo-EM) structure of human SAGA (hSAGA) and show how the arrangement of distinct structural elements results in a globally divergent organization from that of yeast, with a different interface tethering the core module to the TRRAP subunit, resulting in a dramatically altered geometry of functional elements and with the integration of a metazoan-specific splicing module. Our hSAGA structure reveals the presence of an inositol hexakisphosphate (InsP) binding site in TRRAP and an unusual property of its pseudo-(Ψ)PIKK. Finally, we map human disease mutations, thus providing the needed framework for structure-guided drug design of this important therapeutic target for human developmental diseases and cancer. | |||||||||||||||||||||
| 履歴 |
|
- 構造の表示
構造の表示
| ムービー |
ムービービューア |
|---|---|
| 構造ビューア | 分子: MolmilJmol/JSmol |
 UCSF Chimera
UCSF Chimera- ダウンロードとリンク
ダウンロードとリンク
-ダウンロード
| PDBx/mmCIF形式 | 7kts.cif.gz | 2.1 MB | 表示 | PDBx/mmCIF形式 |
|---|---|---|---|---|
| PDB形式 | pdb7kts.ent.gz | 表示 | PDB形式 | |
| PDBx/mmJSON形式 | 7kts.json.gz | ツリー表示 | PDBx/mmJSON形式 | |
| その他 |  その他のダウンロード その他のダウンロード |
-検証レポート
| 文書・要旨 | 7kts_validation.pdf.gz | 1.3 MB | 表示 | wwPDB検証レポート |
|---|---|---|---|---|
| 文書・詳細版 | 7kts_full_validation.pdf.gz | 1.4 MB | 表示 | |
| XML形式データ | 7kts_validation.xml.gz | 154.7 KB | 表示 | |
| CIF形式データ | 7kts_validation.cif.gz | 246.5 KB | 表示 | |
| アーカイブディレクトリ | https://data.pdbj.org/pub/pdb/validation_reports/kt/7ktsftp://data.pdbj.org/pub/pdb/validation_reports/kt/7kts | HTTPS FTP |
-関連構造データ






-リンク
 PDBj
PDBj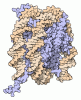

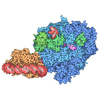
- 集合体
集合体
| 登録構造単位 | 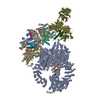
|
|---|---|
| 1 |
|
-要素
-タンパク質 , 8種, 8分子 ABCDFIJN
| #1: タンパク質 | 分子量: 419168.094 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 細胞株: HeLa / 参照: UniProt: F2Z2U4 |
|---|---|
| #2: タンパク質 | 分子量: 66223.047 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: O75529 |
| #3: タンパク質 | 分子量: 88129.070 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q8NEM7 |
| #4: タンパク質 | 分子量: 83013.664 Da / 分子数: 1 / 由来タイプ: 組換発現 由来: (組換発現) Homo sapiens (ヒト), (組換発現) unclassified Rhodococcus (バクテリア)遺伝子: SUPT7L, KIAA0764 / 発現宿主: Homo sapiens (ヒト) / 参照: UniProt: O94864 |
| #6: タンパク質 | 分子量: 62027.703 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q9Y6J9 |
| #9: タンパク質 | 分子量: 35447.500 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: O75486 |
| #10: タンパク質 | 分子量: 37432.531 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q96BN2 |
| #11: タンパク質 | 分子量: 95597.742 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: O15265 |
-Transcription initiation factor TFIID subunit ... , 3種, 3分子 EGH
| #5: タンパク質 | 分子量: 27654.861 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q9HBM6 |
|---|---|
| #7: タンパク質 | 分子量: 17948.467 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q16514 |
| #8: タンパク質 | 分子量: 21731.248 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q12962 |
-Splicing factor 3B subunit ... , 2種, 2分子 ST
| #12: タンパク質 | 分子量: 135718.844 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q15393 |
|---|---|
| #13: タンパク質 | 分子量: 10149.369 Da / 分子数: 1 / 由来タイプ: 天然 / 由来: (天然) Homo sapiens (ヒト) / 参照: UniProt: Q9BWJ5 |
-詳細
| 配列の詳細 | Portions of chains A, D, F and I were not fully discernible in the map, and so many of the residues ...Portions of chains A, D, F and I were not fully discernible in the map, and so many of the residues were modeled as unknown (UNK) due to not knowing the register in these regions. The full sequence of the chains are as follows. Chain A: MAFVATQGAT |
|---|